L’application Data Manager contiendra uniquement:
- datamappings.config
- datamanager.config
- privateKey.xml
- bin:
- Release:
- Fichiers:
- Log:
- Verbose: Dans ce dossier vous trouverez les fichiers log du Data Manager
- Log:
- Fichiers:
- CirrusShield.DataManager.exe
- CirrusShield.DataManager.exe.config
- CirrusShield.Security.dll
- Release:
Pour lancer le data manager, vous devez suivre les étapes suivantes:
- Préparer votre source de données en fichier .csv Les fichiers doivent être encodés en UTF8 et les types de données doivent respecter le format décrit dans la section 3 ci-dessous.
- Paramétrez le datamanager.config et fichiers datamappings.config (voir section 4 dans ce document).
- Lancer le fichier exécutable: CirrusShield.DataManager.exe
- Vérifiez l’erreur de sortie and le fichier de réussite.
| 1. Boolean -Valeurs correctes (insensible à la casse) = 1 – Valeurs incorrectes (insensible à la casse) = 0 | 7. Devise |
| 2. Formats Dates – Le format de Date est: AAAA-MM-JJ – LE format de Date/Heure: AAAA-MM-JJ HH:MM:SS+TZ – où le TZ est le fuseau horaire (Timezone). Example: 2017-01-15 10:00:00+01 | 8. Texte |
| 3. Email | 9. Zone de texte |
| 4. Relation de recherche | 10. Zone de texte (Rich): Html |
| 5. Nombre : – Format: nnnnnnnnnnnnnnnn.nn | 11. URL |
| 6. Pourcent : – Format: nnn.nn |
Relation de Recherche
Lorsque vous importer des données à l’aide du Data Manager, vous pouvez remplir les valeurs du champ “relation de recherche” dans le fichier csv que vous voulez installer dans Cirrus Shield, avec les valeurs du champ Id Externe de l’objet parent, au lieu de les remplir avec les valeurs “Id Cirrus Shield”.
Le champ Id Externe est un champ qui est utilisé comme identifiant d’enregistrement unique d’un système Externe lors de l’importation de données dans l’instance de Cirrus Shield.
Pour définir un champ en tant que champ «Id externe», vous devez cocher la case propriété «Identifiant externe» trouvée lors de la création / mise à jour d’un champ dans la plateforme Cirrus Shield.
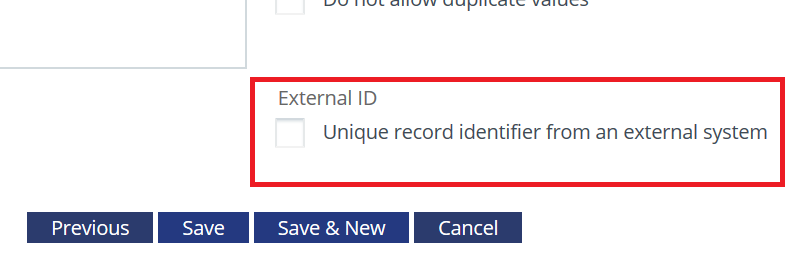
Dans la version actuelle de Cirrus Shield, uniquement le champ Id Externe peut être défini par objet.
Si un champ “Id Externe” est défini sur un objet, les champs “Relation de Recherche” de cet objet doivent être remplit par les valeurs du champ “Id Externe” et non pas par les valeurs ‘Id Cirrus Shield”.
Example:
Définissons sur l’objet standard «Utilisateur» un champ personnalisé «Id Externe d’utilisateur» du type de données «Texte», et vérifions la propriété «Identifiant externe». Créons également un objet personnalisé «Compte».
Ensuite, nous ajouterons 2 utilisateurs de Cirrus Shield ayant les valeurs de champs «Id» (Cirrus Shield Id) et «id Externe d’utilisateur» suivantes:

Si nous désirons importer des enregistrements «Compte» dans l’instance de Cirrus Shield, nous devrions renseigner les champs «Compte», «Relation de recherche» (vers l’objet «Utilisateur»), à l’aide des valeurs du champ «Id externe d’utilisateur» et non pas les valeurs de champ du « Id ” (Cirrus Shield Id).
Le fichier csv contenant les enregistrements de compte à télécharger sera le suivant:

L’enregistrement “Compte 1” aura comme propriétaire l’utilisateur “Noémi Leroy” et le “Compte2” aura comme propriétaire l’utilisateur: “Alice Robert”.
Notez que si vous avez écrit “123457” au lieu de “123456” dans la colonne Id Propriétaire du fichier csv, l’enregistrement ne s’ajoutera pas si aucun utilisateur a comme id Externe “123457”.
Cette section explique les fichiers de configuration du Data Manager. Ces fichiers sont utilisés par le Data Manager au moment de l’exécution pour:
- Définissez l’instance cible de Cirrus Shield dans laquelle les données doivent être chargées à l’aide de l’utilisateur spécifié pour la connexion.
- Définissez le chemin d’accès et les fichiers à utiliser en tant que données source à importer dans l’instance Cirrus Shield correspondante.
- Définissez les correspondances des champs sources (dans les fichiers .csv) avec les champs cibles (dans l’instance de Cirrus Shield)
1. Chemin pour le DataManagerConfig et DataMappingsConfig
Dans CirrusShield.DataManager.exe.config et CirrusShield.DataManager.vshost.exe.config vou devez changer ceci:
<appSettings>
<add key=”DataManagerConfig” value=”C:DataManagerdatamanager.config”/>
<add key=”DataMappingsConfig” value=”C:DataManagerdatamappings.config”/>
</appSettings>
Vous spécifiez le chemin pour datamanager.config et datamappings.config dans la valeur des ces deux clés dans les deux fichiers cités en dessus.
- datamanager.config: le fichier contenant les informations à propos du Data Manager.
- datamappings.config: fichier de definition de la correspondance des champs.
2. Fichier de configuration: datamanager.config
Dans ce fichier, vous devez spécifier:
- Le nom d’utilisateur.
- Le mot de passe de l’utilisateur (valeur cryptée).
- L’URL du Soap Api de l’application pour laquelle le protocol utilisé “http” ou “https” (Biensûr le https est forcément recommandé).
- Le délimiteur CSV (, ou;).
- La taille en vrac (nombre d’enregistrement à ajouter/mettre à jour en même temps).
- L’AutoExit (vrai ou faux): qui indique au data manager s’il doit donner la main à la ligne de commande en terminant le chargement ou s’il doit attendre une action manuelle de l’utilisateur.
Voici quelques exemples qui montrent comment paramétrer le fichier datamanager.config :
<?xml version=”1.0″ encoding=”utf-8″ ?>
<configuration>
<appSettings>
<add key=”UserName” value=”nom.utilisateur@domaine.fr”/>
<add key=”Password” value=”VALEUR_ENCRYPTEE_DU_MOT_DE_PASSE”/>
<add key=”HttpCSInstance” value=”http://localhost:1739/CirrusShieldWS.asmx”/>
<add key=”HttpsCSInstance” value=”https://ws.cirrus-shield.net/CirrusShieldWS.asmx”/>
<add key=”CSPrivateKey” value=”C:DataManagerprivateKey.xml”/>
<add key =”Proxy” value=””/>
<add key =”ProxyUser” value=””/>
<add key =”ProxyPwd ” value=””/>
<add key =”CSVDelimiter” value=”,”/>
<add key=”Bulk” value=”true”/>
<add key=”BulkSize” value=”10″/>
<add key=”AutoExit” value=”true”/>
<add key=”WebServiceProtocol” value=”https”/>
</appSettings>
</configuration>
Note: Pour le cryptage du mot de passe vous aurez besoin de l’outil d’encryptage fournis dans la plateforme de Cirrus Shield:
EncryptDataManagerCirrusShieldUserPassword Vous pouvez trouver cet outil dans “DropboxCirrus ShieldR&DToolsEncryptDataManagerCirrusShieldUserPasswordEncryptionGUI.exe”.
3. Fichier de configuration : datamappings.config
Dans ce fichier, vous pouvez définir l’objet cible dans lequel vous voulez importer vos données, ainsi que spécifier les mappings entre les champs de votre application et les champs de votre fichier csv. Voici un simple mapping:
<map>
<FilePath>C:datasourcePolicies.csv</FilePath>
<ObjectName>Policy</ObjectName>
<Action>Insert</Action>
<MatchingField>Policy_Number</MatchingField>
<Fields>
<Field Column=”POLICY_NUMBER” APIColumn=”Policy_Number” ></Field>
<Field Column=”PRODUCT” APIColumn=”Product” ></Field>
<Field Column=”HOLDER_NUMBER” APIColumn=”Holder_Number” ></Field>
<Field Column=”HOLDER” APIColumn=”Holder” ></Field>
<Field Column=”INSURED_NUMBER” APIColumn=”Insured_Number” ></Field>
<Field Column=”INSURED” APIColumn=”Insured” ></Field>
<Field Column=”PAYER_NUMBER” APIColumn=”Payer_Number” ></Field>
<Field Column=”PAYER” APIColumn=”Payer” ></Field>
<Field Column=”TOTAL_PREMIUM” APIColumn=”Total_Premium” ></Field>
<Field Column=”NUMBER_OF_PAYMENTS” APIColumn=”Number_of_Payments” ></Field>
<Field Column=”COMMISSION” APIColumn=”Commission” ></Field>
<Field Column=”UNPAID_COMMISSION” APIColumn=”Unpaid_Commission” ></Field>
<Field Column=”ACCOUNT_VALUE_LIFE” APIColumn=”Account_Value_Life” ></Field>
<Field Column=”INSURANCE_TERM” APIColumn=”Insurance_Term” ></Field>
<Field Column=”PAYMENT_TERM” APIColumn=”Payment_Term” ></Field>
<Field Column=”POLICY_VALUE” APIColumn=”Policy_Value” ></Field>
</Fields>
<ResultDirectory>C:dataResults</ResultDirectory>
</map>
L’exemple ci-dessus est utilisé pour montrer:
- Le chemin du fichier csv utilisé comme source de donnée à importer.
- Le choix des actions du Data Manager: Insert, Upsert, Update, ou Delete.
- La spécification des champs correspondants utilisés comme clé primaire pour les données.
- La définition du mapping entre les champs du fichier csv et ceux de l’application.
– “Colonne” correspond au nom du champ dans le fichier csv.
– “Colonne API” correspond aux noms des champs dans l’application. - Spécification du chemin d’accès au dossier Résultats dans lequel vous souhaitez stocker les informations de résultat. Ce dossier contiendra un journal des résultats des actions du gestionnaire de données. Un fichier csv sera sauvegardé (nom: datetime-name_of_original_csv.csv) avec les mêmes champs que le fichier csv d’origine, complétés par deux champs supplémentaires: le premier pour la réussite de l’action de chaque enregistrement et le second pour l’erreur message.
4. Action
Avec le Data Manager vous pouvez ajouter, mettre à jour, ajouter et mettre à jour et supprimer des enregistrements.
- Pour ajouter: Vous devez spécifier du système des champs, uniquement le nom de l’enregistrement et l’Id du Propriétaire qui est L’Id interne de l’utilisateur qui possède cet enregistrement ou l’Id externe de l’utilisateur si il existe.
- Par défaut, les champs CreatedBy et ModifiedBy seront assignés à l’utilisateur qui importe ses données spécifié dans datamanager.config
- Pour mettre à jour: Si vous ne voulez pas mettre à jour tous les champs d’un enregistrement vous pouvez choisir les champs à mapper
- Vous devez faire attention à faire correspondre les bons champs, ça doit être unique si vous voulez mettre à jour un enregistrement spécifique.
- Important: Vous devez garder dans datamappings.confi.only les champs mis à jours, si vous garder tous les champs, le système va prendre les champs qui n’existe pas dans le fichier csv et le considérer comme invalide et les mettra à jour comme invalides.
- Pour ajouter et mettre à jour: Il faut faire attention au champs à mapper et à faire correspondre, s’il ne sont pas uniques, le data manager mettra à jour tous les champs qui ont la même valeur de champ correspondant. Cette action va permettre aux utilisateurs de Mettre à jour des enregistrements qui existe déjà et en plus d’ajouter des nouveaux qui n’existent pas.
- Pour supprimer: Vous devez garder uniquement une colonne dans votre fichier csv. Le choix de cette colonne dépend de si vous voulez supprimer un enregistrement spécifique ou un ensemble d’enregistrements. S’il s’agit d’un enregistrement spécifique, la seule colonne qui doit être présente dans votre fichier csv est un champ qui est unique. S’il s’agit d’un ensemble d’enregistrements qui ont par exemple Numéro = 1, la colonne qui doit rester dans le fichier csv est Numéro avec la valeur 1.
Pour lancer le data manager, après la mise à jour des fichiers comme décrit dans le guide, vous devez double-cliquez sur CirrusShield.DataManager.exe.
En utilisant le data manager, il se peut que vous tombez sur des erreurs et des problèmes. Vous trouvez ci-dessous quelques uns:
Erreurs Générales dans la ligne de Commande:
- « There is an error during the processing of the file»
Cette erreur est par taille de bloc ou en vrac, par exemple. Si vous avez la taille en bloc = 2000 et qu’il y a une erreur dans 500 enregistrements sur 2000, le message d’erreur ne s’affiche qu’une seule fois pour ces 2000 enregistrements.
Pour les deuxièmes enregistrements en bloc (2000 enregistrements pour ex.), Vous verrez un deuxième message d’erreur en cas d’erreur dans un enregistrement sur 2000 et dans le cas d’une erreur dans 2000 enregistrements sur 2000. - Vous pouvez avoir une erreur fatale si vous avez par erreur un “enter” dans un champ, cela provoquera une erreur système.
- Une autre erreur peut provenir de la connexion entre le service Web utilisé par le data manager et la base de données, en particulier si la base de données est installée sur un serveur distinct.
- Si le fichier csv d’une carte n’existe pas, le data manager enregistre ces informations dans «Fichiers LogVerbose» et passe au fichier csv suivant dans les mappages.
Erreur dans le fichier de résultat
Cette erreur s’affichera en cas de valeur non valide pour un champ. Vous pouvez voir les détails de l’erreur dans le CSV généré dans le dossier des résultats, tels que:
- Error_MSG_Field_Required : Valeur non-existante pour un champ obligatoire.
- Error_MSG_Value_entered_not_valid: Format non-valide d’une valeur pour un spécifique type de champ
- Exemples :
- “Date_of_Birth:Error_MSG_Value_entered_not_valid”: Ce message apparait si le type est par exemple Date mais le format n’est pas correcte (comme mentionné dans la section 4).
- “Email: Error_MSG_Value_entered_not_valid”:
Ce message apparaît si le type est par exemple Email mais la valeur n’est pas un email correct.
- Exemples :
- “This Record does not exist”: Ce message apparaît si vous mettez à jour un enregistrement qui n’existe pas.
- “This record already exists”: Ce message apparaît si vous ajouter un enregistrement qui existe déjà.
- Certains Champs de liste de sélection contiennent des valeurs invalides:
- Cette erreur s’est produit lorsqu’une valeur de liste de choix dans le fichier csv n’existait pas dans Cirrus Shield.
- Si l’enregistrement que vous ajoutez a un champ qui est relié à un autre objet. (un champ “Relation de Recherche”) et l’enregistrement qui lui est relié n’existe pas, l’enregistrement ne sera pas inséré.